Abstract:
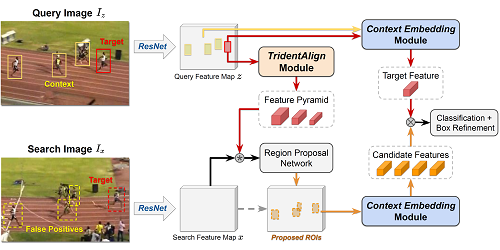
Recent advances in Siamese network-based visual tracking methods have enabled high performance on numerous tracking benchmarks. However, extensive scale variations of the target object and distractor objects with similar categories have consistently posed challenges in visual tracking. To address these persisting issues, we propose novel TridentAlign and context embedding modules for Siamese network-based visual tracking methods. The TridentAlign module facilitates adaptability to extensive scale variations and large deformations of the target, where it pools the feature representation of the target object into multiple spatial dimensions to form a feature pyramid, which is then utilized in the region proposal stage. Meanwhile, context embedding module aims to discriminate the target from distractor objects by accounting for the global context information among objects. The context embedding module extracts and embeds the global context information of a given frame into a local feature representation such that the information can be utilized in the final classification stage. Experimental results obtained on multiple benchmark datasets show that the performance of the proposed tracker is comparable to that of state-of-the-art trackers, while the proposed tracker runs at real-time speed.