Abstract:
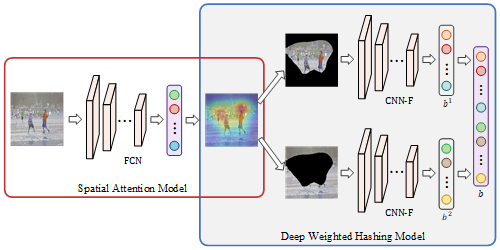
Fine-grained image retrieval is a fundamental and challenging problem in computer vision due to the intra-class diversities and inter-class confusions. Existing hashing-based approaches employed convolutional neural networks (CNNs) to learn hash codes for fast fine-grained image retrieval, which are limited by the inherent locality constrain of the convolution operations and yield sub-optimal performance. Recently, transformers have shown colossal potential on vision tasks for their excellent capacity to capture long-range visual dependencies. Therefore, in this paper, we take the first step to exploit the vision transformer-based hashing network for fine-grained image retrieval. We propose the SwinFGHash, which takes advantage of transformer-based architecture to model the feature interactions among the spatially distant areas, e.g., the head and the tail of a bird on an image, thus improving the fine-grained discrimination of the generated hash codes. Besides, we enhance the critical region localization ability of SwinFGHash by designing a Global with Local (GwL) feature learning module, which preserves subtle yet discriminative features for fine-grained retrieval. Extensive experiments on benchmark datasets show that our SwinFGHash significantly outperforms existing state-of-the-art baselines in fine-grained image retrieval.