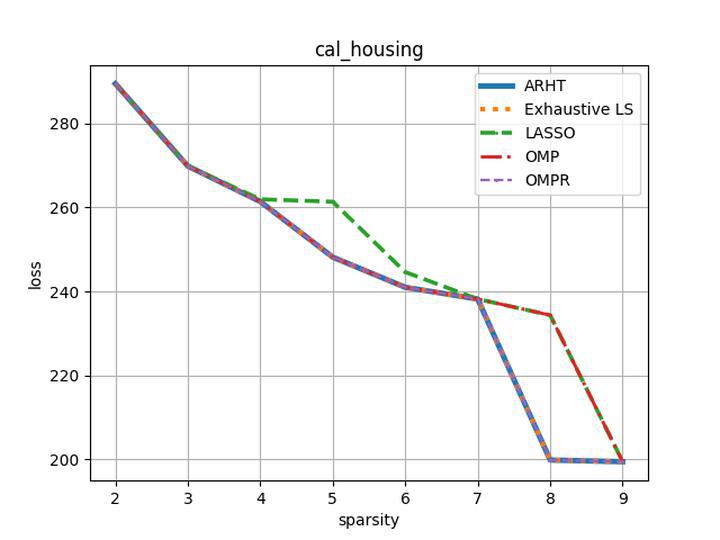
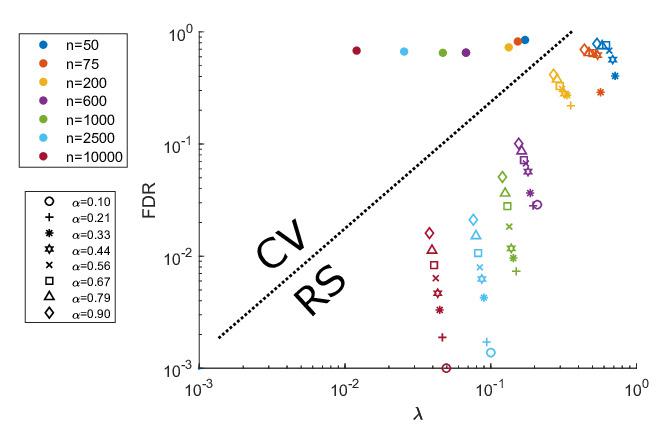
Abstract:
As in standard linear regression, in truncated linear regression, we are given access to observations (A_i, y_i)_i whose dependent variable equals y_i= A_i^{\rm T} \cdot x^* + \eta_i, where x^* is some fixed unknown vector of interest and \eta_i is independent noise; except we are only given an observation if its dependent variable y_i lies in some "truncation set" S \subset \mathbb{R}. The goal is to recover x^* under some favorable conditions on the A_i's and the noise distribution. We prove that there exists a computationally and statistically efficient method for recovering k-sparse n-dimensional vectors x^* from m truncated samples, which attains an optimal \ell_2 reconstruction error of O(\sqrt{(k \log n)/m}). As a corollary, our guarantees imply a computationally efficient and information-theoretically optimal algorithm for compressed sensing with truncation, such as that which may arise from measurement saturation effects. Our result follows from a statistical and computational analysis of the Stochastic Gradient Descent (SGD) algorithm for solving a natural adaption of the LASSO optimization problem that accommodates truncation. This generalizes the works of both: (1) [Daskalakis et al. 2018], where no regularization is needed due to the low dimensionality of the data, and (2) [Wainright 2009], where the objective function is simple due to the absence of truncation. In order to deal with both truncation and high-dimensionality at the same time, we develop new techniques that not only generalize the existing ones but we believe are of independent interest.