Abstract:
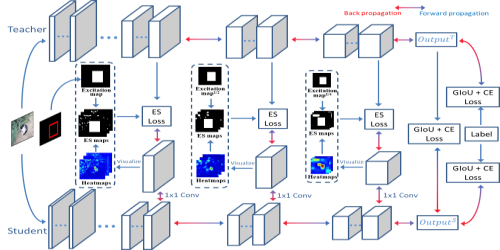
Knowledge distillation based deep model compression has been actively pursued in order to obtain improved performance on specified student architectures by distilling knowledge from deeper networks. Among various methods, attention based knowledge distillation has shown great promise on large datasets. However, this approach is limited by hand-designed attention functions such as absolute sum. We address this shortcoming by proposing trainable attention methods that can be used to obtain improved performance while distilling knowledge from teacher to student. We also show that, using dense connections efficiently between attention modules, we can further improve the student’s performance. Our approach, when applied to ResNet50(teacher)-MobileNetv1(student) pair on ImageNet dataset, has a reduction of 9.6% in Top-1 error rate over the previous state-of-the-art method.