Abstract:
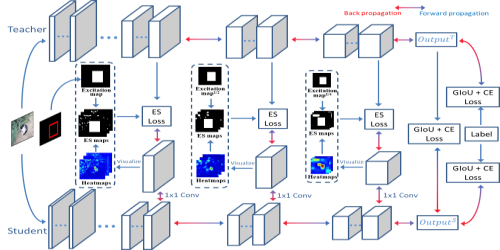
Knowledge Distillation is becoming one of the primary trends among neural network compression algorithms to improve the generalization performance of a smaller student model with guidance from a larger teacher model. This momentous rise in applications of knowledge distillation is accompanied by the introduction of numerous algorithms for distilling the knowledge such as soft targets and hint layers. Despite this advancement in different techniques for distilling the knowledge, the aggregation of different paths for distillation has not been studied comprehensively. This is of particular significance, not only because different paths have different importance, but also due to the fact that some paths might have negative effects on the generalization performance of the student model. Hence, we need to adaptively adjust the importance of each path to maximize the impact of distillation on the student model. In this paper, we explore different approaches for aggregating these different paths and introduce our proposed adaptive approach based on multitask learning methods. We empirically demonstrate the effectiveness of our proposed approach over other baselines in the applications of knowledge distillation for classification, semantic segmentation, and object detection tasks.