Abstract:
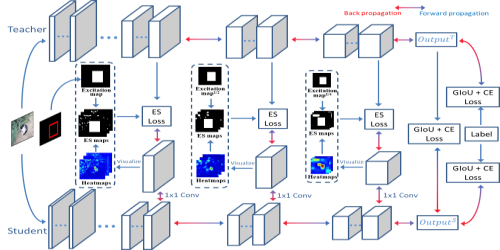
Recent object re-identification approaches tend to use heavy models (e.g., ResNet-50 or ResNet-101) to guarantee performance, which requires massive computations. Although knowledge distillation (KD) methods can be applied to learn light student models from heavy teacher models, numerous existing KD research has shown that significant architectural differences between students and teachers prevent students from achieving good accuracy. For that, we propose a joint distillation and pruning (JDP) method to learn teacher-like and light (TLL) students for object re-identification. Given a heavy teacher, JDP applies a student that holds the same overall architecture but a tiny local adjustment. Specifically, we design a pruner-convolution-pruner (PCP) block to replace a K ×K convolutional layer of the student network. The pruner is a 1×1 convolutional layer and initialized identity matrices to maintain the original output. During the student training phase, the student is jointly supervised by the KD loss and group LASSO loss functions. The KD loss function promotes the student to learn dark knowledge from the teacher. The group LASSO loss function enforces pruners to realize the channel sparsity for filtering unimportant channels. A PCP block can be simplified into a light convolutional layer during the testing phase since multiple linearly convolutional layers in series can be equivalently merged into one convolutional layer. As a result, a TLL student is acquired. Extensive experiments show that our JDP method has superiority in terms of accuracy and computations , e.g., on the Veri-776 dataset, given the ResNet-101 as a teacher, our TLL student saves 80.00% parameters and 78.52% FLOPs, while the mAP only drops by 0.17%.