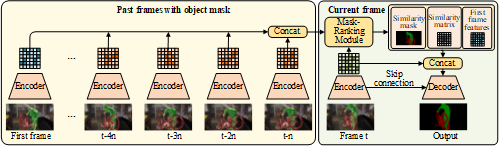
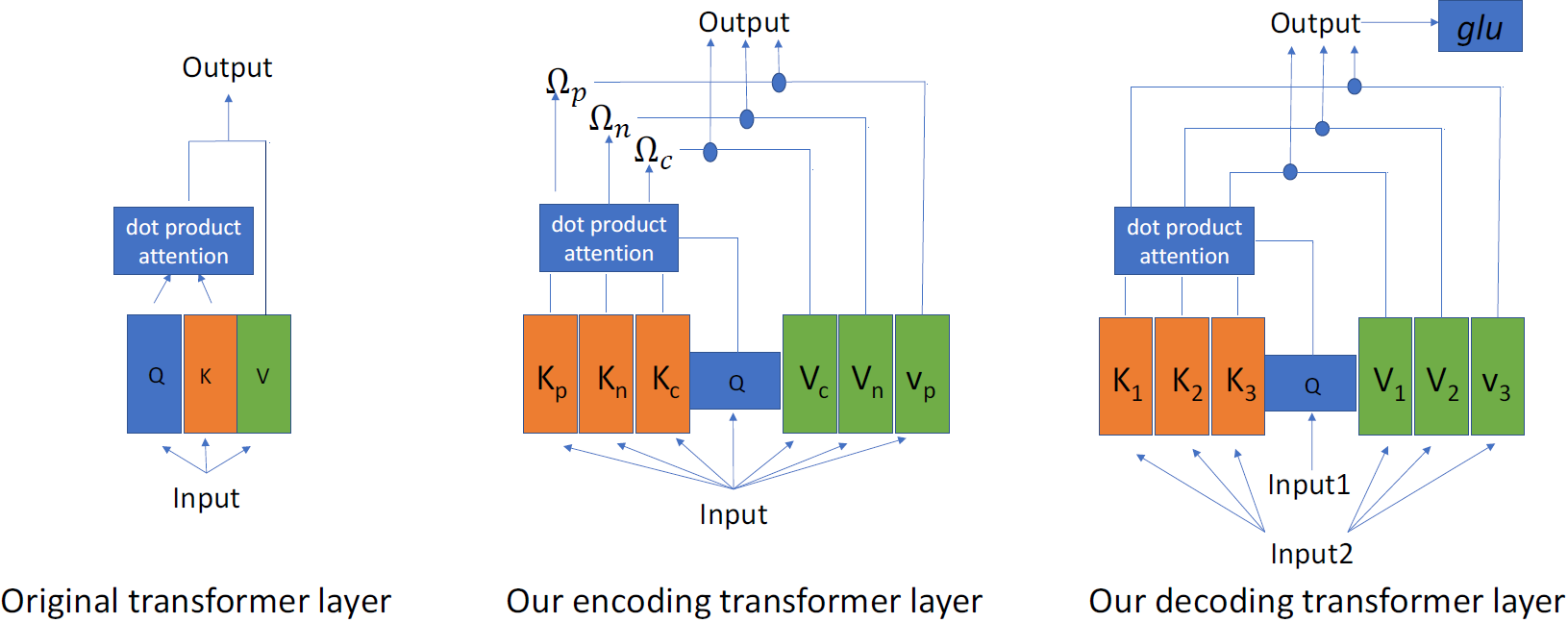
Abstract:
Unpaired multimodal image-to-image translation is a task of converting a given image in a source domain into diverse images in a target domain. We propose two approaches to produce high-quality and diverse images. First, we propose to encode a source image conditioned on a given target style feature. It allows our model to generate higher-quality images than existing models, which are not based on this method. Second, we propose an information-theoretic loss function that effectively captures styles in an image. It allows our model to learn complex high-level styles rather than simple low-level styles, and generate perceptually diverse images. We show our proposed model achieves state-of-the-art performance through extensive experiments on various real-world datasets.