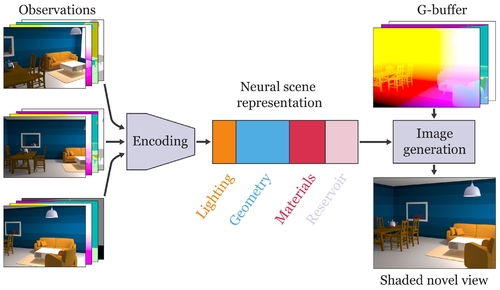
Abstract:
Most image captioning models aim to generate captions based solely on the input image. However images that are similar to the given input image contain variations of the same or similar concepts as the input image. Thus, aggregating information over similar images could be used to improve image captioning models, by strengthening or inferring concepts that are in the input image. In this paper, we propose an image captioning model based on KNN graphs composed of the input image and its similar images, where each node denotes an image or a caption. An attention-in-attention (AiA) model is developed to refine the node representations. Using the refined features significantly improves the baseline performance, eg, CIDEr score obtained by Updown model increases from 120.1 to 125.6. Compared with the state-of-the-art performance, our proposed method obtains 129.3 of CIDEr and 22.6 of SPICE on Karpathy's test split, which is competitive with the models that employ fine-grained image features such as scene graphs and image parsing trees.