Abstract:
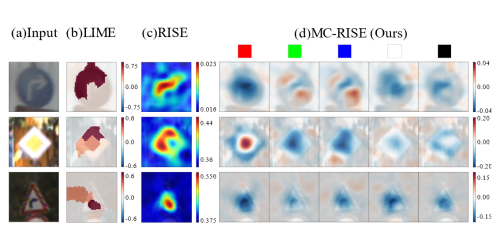
Numerous interpretability methods have been developed to visually explain the behavior of complex machine learning models by estimating parts of the input image that are critical for the model's prediction. We propose a general pipeline of enhancing visual explanations using image transformations (EVET). EVET considers transformations of the original input image to refine the critical input region based on an intuitive rationale that the region estimated to be important in variously transformed inputs is more important. Our proposed EVET is applicable to existing visual explanation methods without modification. We validate the effectiveness of the proposed method qualitatively and quantitatively to show that the resulting explanation method outperforms the original in terms of faithfulness, localization, and stability. We also demonstrate that EVET can be used to achieve desirable performance with a low computational cost. For example, EVET-applied Grad-CAM achieves performance comparable to Score-CAM, which is the state-ofthe-art activation-based explanation method, while reducing execution time by more than 90% on VOC, COCO, and ImageNet.