Abstract:
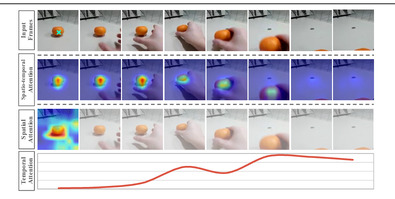
Multi-modal cues presented in videos are usually beneficial for the challenging video-text retrieval task on internet-scale datasets. Recent video retrieval methods take advantage of multi-modal cues by aggregating them to holistic high-level semantics for matching with text representations in a global view. In contrast to this global alignment, the local alignment of detailed semantics encoded within both multi-modal cues and distinct phrases is still not well conducted. Thus, in this paper, we leverage the hierarchical video-text alignment to fully explore the detailed diverse characteristics in multi-modal cues for fine-grained alignment with local semantics from phrases, as well as to capture a high-level semantic correspondence. Specifically, multi-step attention is learned for progressively comprehensive local alignment and a holistic transformer is utilized to summarize multi-modal cues for global alignment. With hierarchical alignment, our model outperforms state-of-the-art methods on three public video retrieval datasets.