Abstract:
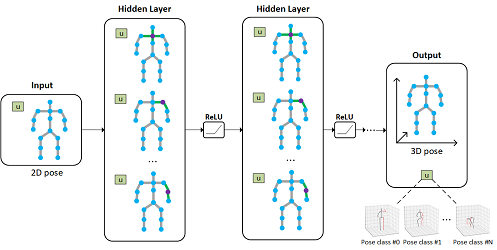
Graph neural networks (GNNs) have been widely used in the 3D human pose estimation task, since the pose representation of a human body can be naturally modeled by the graph structure. Generally, most of the existing GNN-based models utilize the restricted receptive fields of filters and single-scale information, while neglecting the valuable multi-scale contextual information. To tackle this issue, we propose a novel Graph Transformer Encoder-Decoder with Atrous Convolution, named PoseGTAC, to effectively extract multi-scale context and long-range information. In our proposed PoseGTAC model, Graph Atrous Convolution (GAC) and Graph Transformer Layer (GTL), respectively for the extraction of local multi-scale and global long-range information, are combined and stacked in an encoder-decoder structure, where graph pooling and unpooling are adopted for the interaction of multi-scale information from local to global (e.g., part-scale and body-scale). Extensive experiments on the Human3.6M and MPI-INF-3DHP datasets demonstrate that the proposed PoseGTAC model exceeds all previous methods and achieves state-of-the-art performance.