Abstract:
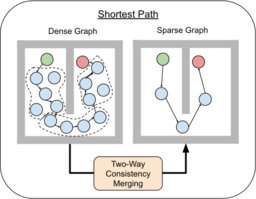
Current image-based reinforcement learning (RL) algorithms typically operate on the whole image without performing object-level reasoning. This leads to inefficient goal sampling and ineffective reward functions. In this paper, we improve upon previous visual self-supervised RL by incorporating object-level reasoning and occlusion reasoning. Specifically, we use unknown object segmentation to ignore distractors in the scene for better reward computation and goal generation; we further enable occlusion reasoning by employing a novel auxiliary loss and training scheme. We demonstrate that our proposed algorithm, ROLL (Reinforcement learning with Object Level Learning), learns dramatically faster and achieves better final performance compared with previous methods in several simulated visual control tasks. Project video and code are available at https://sites.google.com/andrew.cmu.edu/roll.