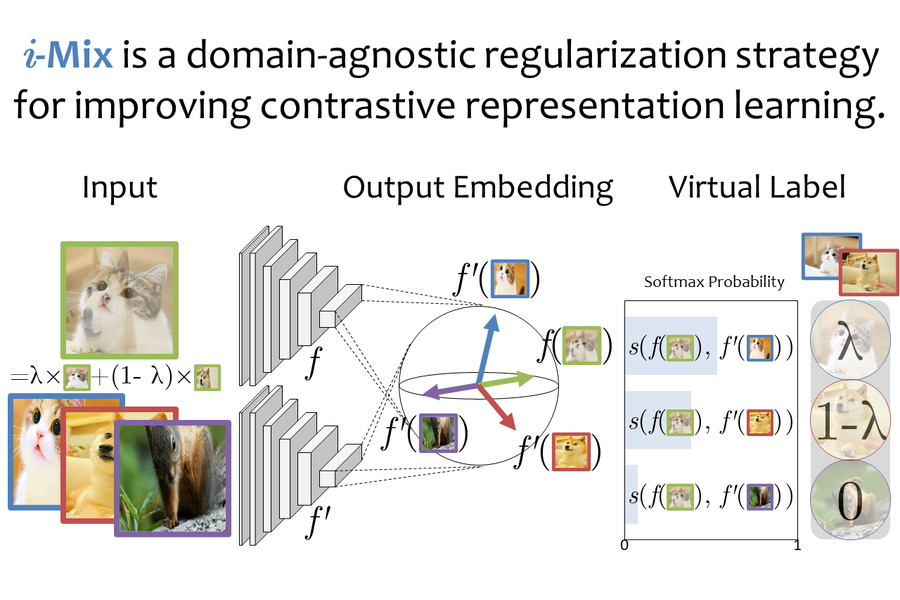
Abstract:
Self-supervised representation learning approaches have recently surpassed their supervised learning counterparts on downstream tasks like object detection and image classification. Somewhat mysteriously the recent gains in performance come from training instance classification models, treating each image and it's augmented versions as samples of a single class. In this work, we first present quantitative experiments to demystify these gains. We demonstrate that approaches like MOCO and PIRL learn occlusion-invariant representations. However, they fail to capture viewpoint and category instance invariance which are crucial components for object recognition. Second, we demonstrate that these approaches obtain further gains from access to a clean object-centric training dataset like Imagenet. Finally, we propose an approach to leverage unstructured videos to learn representations that possess higher viewpoint invariance. Our results show that the learned representations outperform MOCOv2 trained on the same data in terms of invariances encoded and the performance on downstream image classification and semantic segmentation tasks.