Abstract:
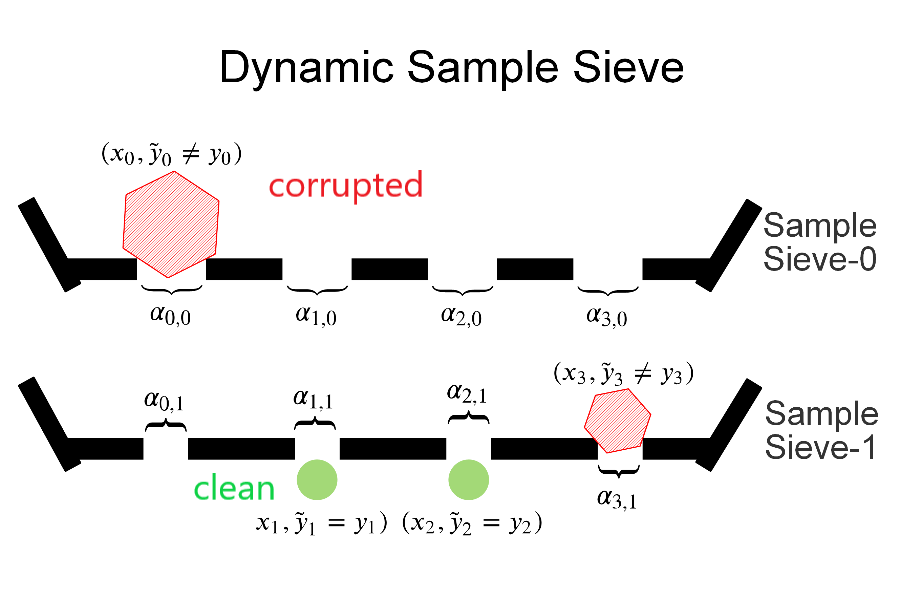
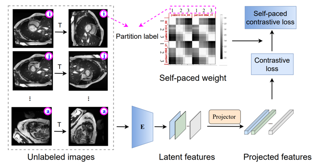
Data cleansing is a well studied strategy for cleaning erroneous labels in datasets, which has not yet been widely adopted in Music Information Retrieval.Previously proposed data cleansing models do not consider structured (e.g. time varying) labels, such as those common to music data.We propose a novel data cleansing model for time-varying, structured labels which exploits the local structure of the labels, and demonstrate its usefulness for vocal note event annotations in music.Our model is trained in a contrastive learning manner by automatically contrasting likely correct labels pairs against local deformations of them.We demonstrate that the accuracy of a transcription model improves greatly when trained using our proposed data cleaning strategy compared with the accuracy when trained using the original dataset.Additionally we use our model to estimate the annotation error rates in the DALI dataset, and highlight other potential uses for this type of model.