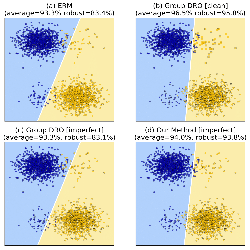
Abstract:
The process of collecting and annotating training data may introduce distribution artifacts which may limit the ability of models to learn correct generalization behavior. We identify failure modes of SOTA relation extraction (RE) models trained on TACRED, which we attribute to limitations in the data annotation process. We collect and annotate a challenge-set we call Challenging RE (CRE), based on naturally occurring corpus examples, to benchmark this behavior. Our experiments with four state-of-the-art RE models show that they have indeed adopted shallow heuristics that do not generalize to the challenge-set data. Further, we find that alternative question answering modeling performs significantly better than the SOTA models on the challenge-set, despite worse overall TACRED performance. By adding some of the challenge data as training examples, the performance of the model improves. Finally, we provide concrete suggestion on how to improve RE data collection to alleviate this behavior.