Abstract:
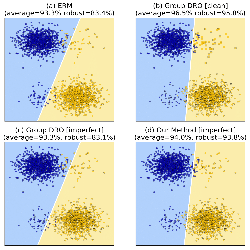
Large neural models have demonstrated human-level performance on language and vision benchmarks such as ImageNet and Stanford Natural Language Inference (SNLI). Yet, their performance degrades considerably when tested on adversarial or out-of-distribution samples. This raises the question of whether these models have learned to solve a dataset rather than the underlying task by overfitting on spurious dataset biases.
We investigate one recently proposed approach, AFLite, which adversarially filters such dataset biases, as a means to mitigate the prevalent overestimation of machine performance. We provide a theoretical understanding for AFLite, by situating it in the generalized framework for optimum bias reduction. Our experiments show that as a result of the substantial reduction of these biases, models trained on the filtered datasets yield better generalization to out-of-distribution tasks, especially when the benchmarks used for training are over-populated with biased samples. We show that AFLite is broadly applicable to a variety of both real and synthetic datasets for reduction of measurable dataset biases and provide extensive supporting analyses. Finally, filtering results in a large drop in model performance (e.g., from 92% to 62% for SNLI), while human performance still remains high. Our work thus shows that such filtered datasets can pose new research challenges for robust generalization by serving as upgraded benchmarks.