Abstract:
An important problem in machine auditory perception is to recognize and detect sound events. In this paper, we propose a sequential self-teaching
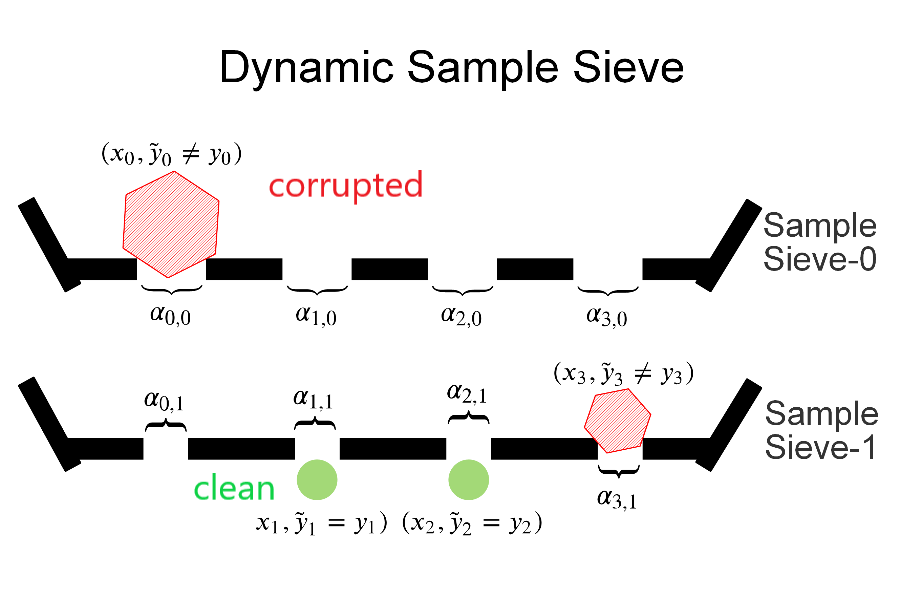
approach to learn sounds. Our main proposition is that it is harder to learn sounds in adverse situations such as from weakly labeled or noisy labeled
data and in these situations a single stage of learning is not sufficient. Our proposal is a sequential stage-wise learning process that improves generalization capabilities of a given modeling system. We justify this via technical results. On
Audioset, the largest sound events dataset, our sequential learning approach can lead to up to 9% improvement in performance. A comprehensive evaluation also shows that the model leads to
improved transferability of knowledge from previously trained models, thereby leading to improved generalization capabilities on transfer learning tasks as well.