Abstract:
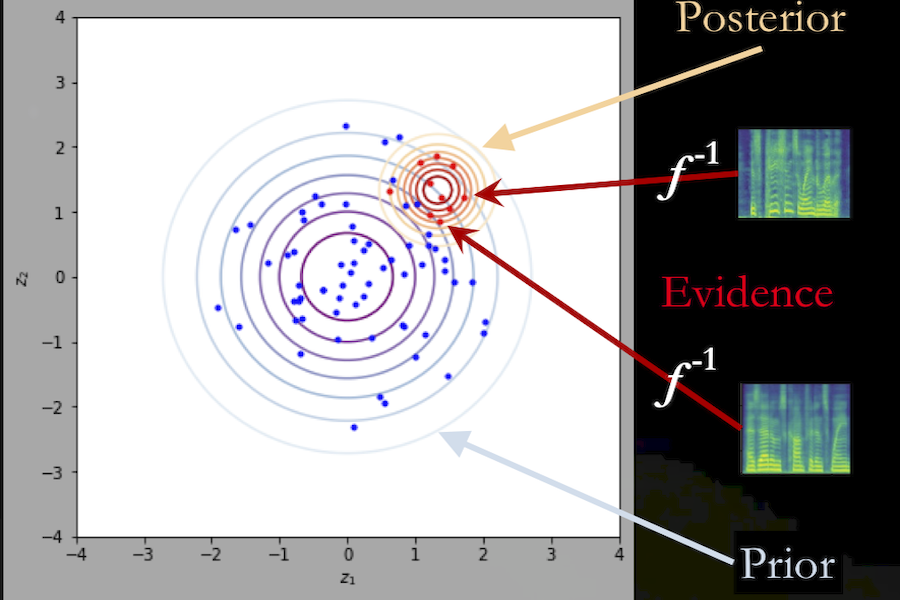
We present a novel generative model that combines state-of-the-art neural text- to-speech (TTS) with semi-supervised probabilistic latent variable models. By providing partial supervision to some of the latent variables, we are able to force them to take on consistent and interpretable purposes, which previously hasn’t been possible with purely unsupervised methods. We demonstrate that our model is able to reliably discover and control important but rarely labelled attributes of speech, such as affect and speaking rate, with as little as 1% (30 minutes) supervision. Even at such low supervision levels we do not observe a degradation of synthesis quality compared to a state-of-the-art baseline. We will release audio samples at https://google.github.io/tacotron/publications/semisupervised_generative_modeling_for_controllable_speech_synthesis/.