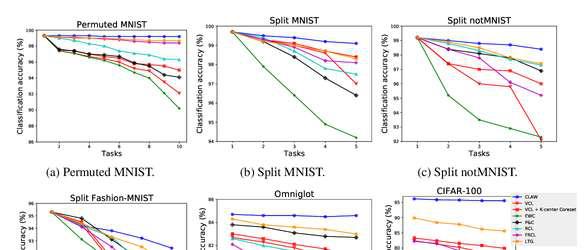
Abstract:
In the last few years, Gradient Boosting Decision Trees (GBDTs) have been widely used in various applications such as online advertising and spam filtering. However, GBDT training is often a key performance bottleneck for such data science pipelines, especially for training a large number of deep trees on large data sets. Thus, many parallel and distributed GBDT systems have been researched and developed to accelerate the training process. In this survey paper, we review the recent GBDT systems with respect to accelerations with emerging hardware as well as cluster computing, and compare the advantages and disadvantages of the existing implementations. Finally, we present the research opportunities and challenges in designing fast next generation GBDT systems.