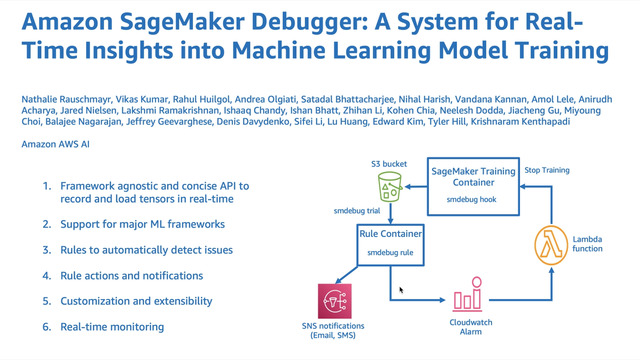
Abstract:
Software composition analysis depends on database of open-source library vulerabilities, curated by security researchers using various sources, such as bug tracking systems, commits, and mailing lists. We report the design and implementation of a machine learning system to help the curation by by automatically predicting the vulnerability-relatedness of each data item. It supports a complete pipeline from data collection, model training and prediction, to the validation of new models before deployment. It is executed iteratively to generate better models as new input data become available. We use self-training to significantly and automatically increase the size of the training dataset, opportunistically maximizing the improvement in the models’ quality at each iteration. We devised new deployment stability metric to evaluate the quality of the new models before deployment into production, which helped to discover an error. We experimentally evaluate the improvement in the performance of the models in one iteration, with 27.59