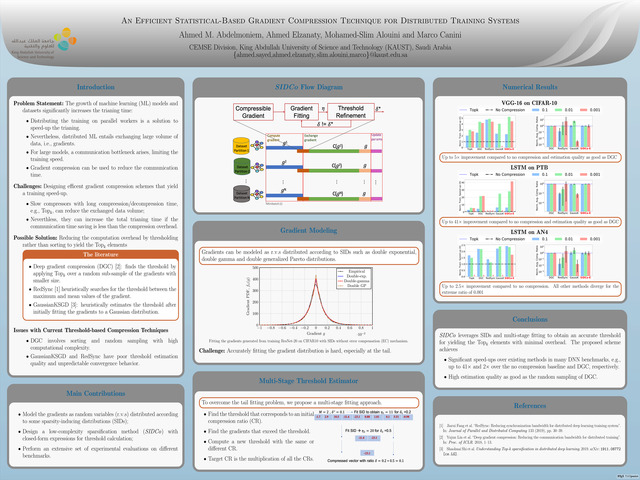
Abstract:
In this paper we study how neural network architecture affects the speed of training. We introduce a simple concept called gradient confusion to help formally analyze this. When confusion is high, stochastic gradients produced by different data samples may be negatively correlated, slowing down convergence. But when gradient confusion is low, data samples interact harmoniously, and training proceeds quickly. Through novel theoretical and experimental results, we show how the neural net architecture affects gradient confusion, and thus the efficiency of training. We show that for popular initialization techniques used in deep learning, increasing the width of neural networks leads to lower gradient confusion, and thus easier model training. On the other hand, increasing the depth of neural networks has the opposite effect. Finally, we observe that the combination of batch normalization and skip connections reduces gradient confusion, which helps reduce the training burden of very deep networks.