Abstract:
Annotating datasets is one of the main costs in nowadays supervised learning.
The goal of weak supervision is to enable models to learn using only forms of
labelling which are cheaper to collect, as partial labelling. This is a type of
incomplete annotation where, for each datapoint, supervision is cast as a set
of labels containing the real one. The problem of supervised learning with
partial labelling has been studied for specific instances such as
classification, multi-label, ranking or segmentation, but a general framework
is still missing. This paper provides a unified framework based on structured
prediction and on the concept of {\em infimum loss} to deal with partial
labelling over a wide family of learning problems and loss functions. The
framework leads naturally to explicit algorithms that can be easily
implemented and for which proved statistical consistency and learning rates.
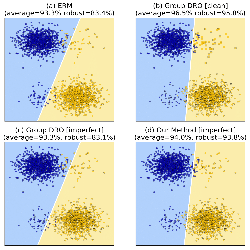
Experiments confirm the superiority of the proposed approach over commonly
used baselines.