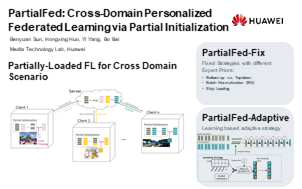
Abstract:
Federated learning enables collaborative training of machine learning models under strict privacy restrictions and federated text-to-speech aims to synthesize natural speech of multiple users with a few audio training samples stored in their devices locally. However, federated text-to-speech faces several challenges: very few training samples from each speaker are available, training samples are all stored in local device of each user, and global model is vulnerable to various attacks. In this paper, we propose a novel federated learning architecture based on continual learning approaches to overcome the difficulties above. Specifically, 1) we use gradual pruning masks to isolate parameters for preserving speakers' tones; 2) we apply selective masks for effectively reusing knowledge from tasks; 3) a private speaker embedding is introduced to keep users' privacy. Experiments on a reduced VCTK dataset demonstrate the effectiveness of FedSpeech: it nearly matches multi-task training in terms of multi-speaker speech quality; moreover, it sufficiently retains the speakers' tones and even outperforms the multi-task training in the speaker similarity experiment.