Abstract:
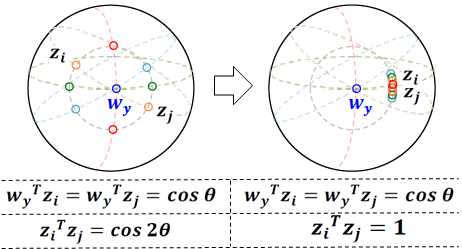
Real-world contains an overwhelmingly large number of object classes, learning all of which at once is infeasible. Few-shot learning provides a promising learning paradigm due to its ability to quickly adapt to novel out of order distributions with only a few samples. Recent works show that simply learning a good feature embedding can outperform more sophisticated meta-learning and metric learning algorithms for few-shot learning. This paper proposes a self supervised knowledge distillation approach, which learns a strong equivariant feature embedding for few shot learning, by faithfully encoding inter-class relationships and preserving intra class diversity. To this end, we follow a two-stage learning process: first, we train our model using a self-supervised auxiliary loss to maximize the entropy of the feature embedding, thus creating an optimal output manifold. In the second stage, we minimize the entropy on feature embedding by bringing self-supervised positive twins together, while constraining the learned manifold with a student-teacher distillation. Our experiments show that, even in the first stage, features learnt by self-supervision can outperform current state-of-the-art methods, with further gains achieved by our second stage distillation process.