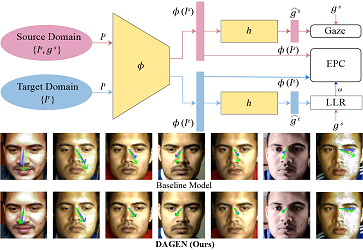
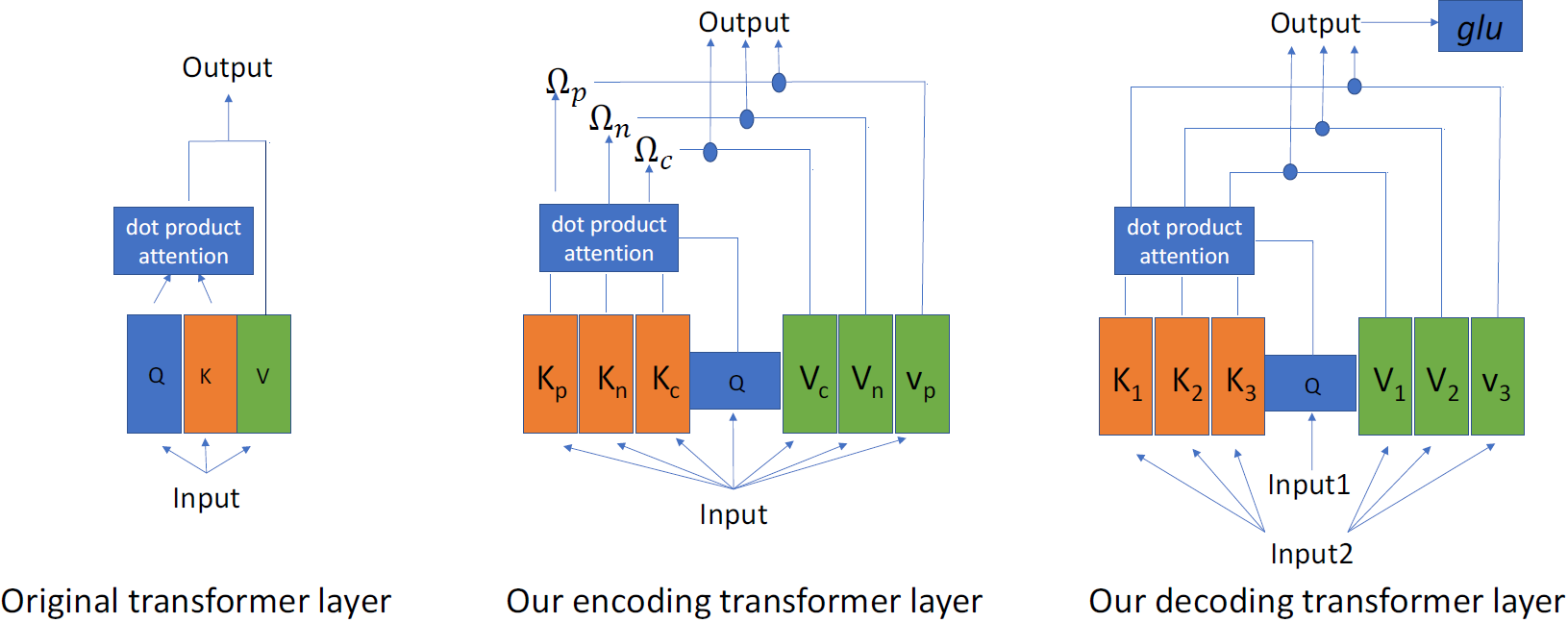
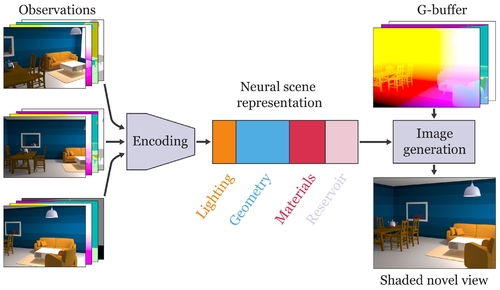
Abstract:
Various styles naturally exist in an image domain. To generate images with certain style, previous works would usually feed a style encoding as an input to the network. However, a fixed network may lack the capability to present different styles in the target domain precisely, and the style input may also lose its impact along the generation process. In this paper, we propose Guided Filter GAN for multi-modal image-to-image translation via guided filter generation, in which filters at convolutional and deconvolutional layers are constructed dynamically from the style representation from either a target domain image or random distribution. Compared to conventional treatment of style representations being network input, the proposed approach amplifies the guidance of the given style meanwhile enhances the capacity of with dynamic parameters to adapt to different styles. We demonstrate the effectiveness of our Guided Filter GAN on various image-to-image translation tasks, where the experimental results show our approach could precisely render a reference style onto the conditional image and generate images with high fidelity and large diversity in terms of FID and LPIPS metric.