Abstract:
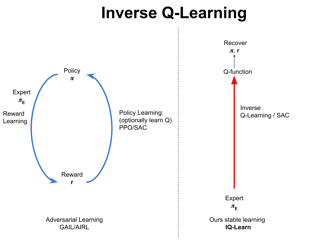
We consider large-scale Markov decision processes with an unknown cost function and address the problem of learning a policy from a finite set of expert demonstrations.
We assume that the learner is not allowed to interact with the expert and has no access to reinforcement signal of any kind.
Existing inverse reinforcement learning methods come with strong theoretical guarantees, but are computationally expensive, while state-of-the-art policy optimization algorithms achieve significant empirical success, but are hampered by limited theoretical understanding.
To bridge the gap between theory and practice, we introduce a novel bilinear saddle-point framework using Lagrangian duality.
The proposed primal-dual viewpoint allows us to develop a model-free provably efficient algorithm through the lens of stochastic convex optimization. The method enjoys the advantages of simplicity of implementation, low memory requirements, and computational and sample complexities independent of the number of states. We further present an equivalent no-regret online-learning interpretation.