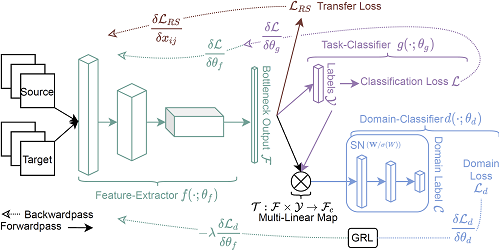
Abstract:
Despite the remarkable empirical performance of deep learning models, their vulnerability to adversarial examples has been revealed in many studies. They are prone to make a susceptible prediction to the input with imperceptible adversarial perturbation. Although recent works have remarkably improved the model's robustness under the adversarial training strategy, an evident gap between the natural accuracy and adversarial robustness inevitably exists. In order to mitigate this problem, in this paper, we assume that the robust and non-robust representations are two basic ingredients entangled in the integral representation. For achieving adversarial robustness, the robust representations of natural and adversarial examples should be disentangled from the non-robust part and the alignment of the robust representations can bridge the gap between accuracy and robustness. Inspired by this motivation, we propose a novel defense method called Deep Robust Representation Disentanglement Network (DRRDN). Specifically, DRRDN employs a disentangler to extract and align the robust representations from both adversarial and natural examples. Theoretical analysis guarantees the mitigation of the trade-off between robustness and accuracy with good disentanglement and alignment performance. Experimental results on benchmark datasets finally demonstrate the empirical superiority of our method.