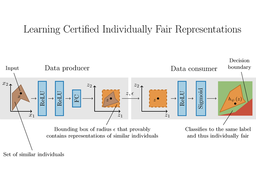
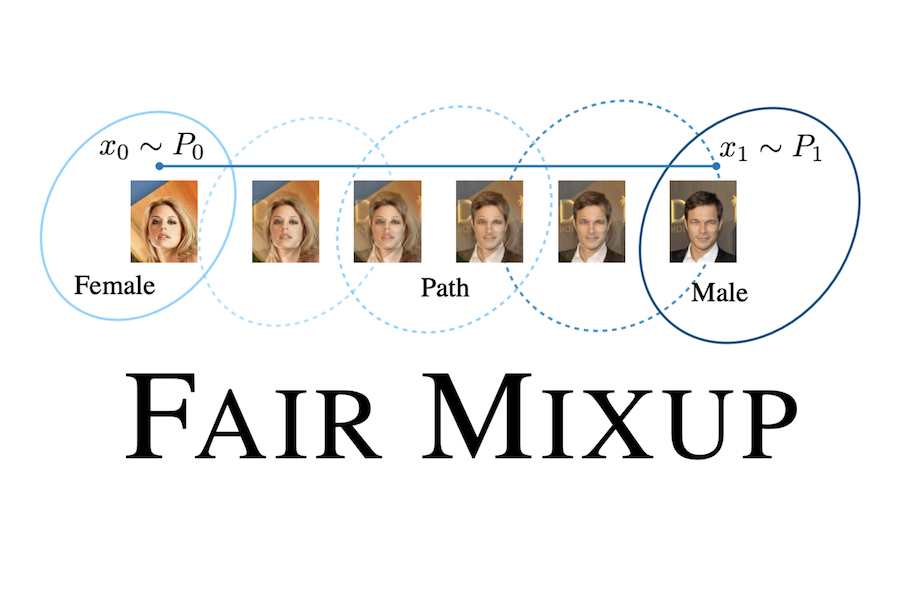
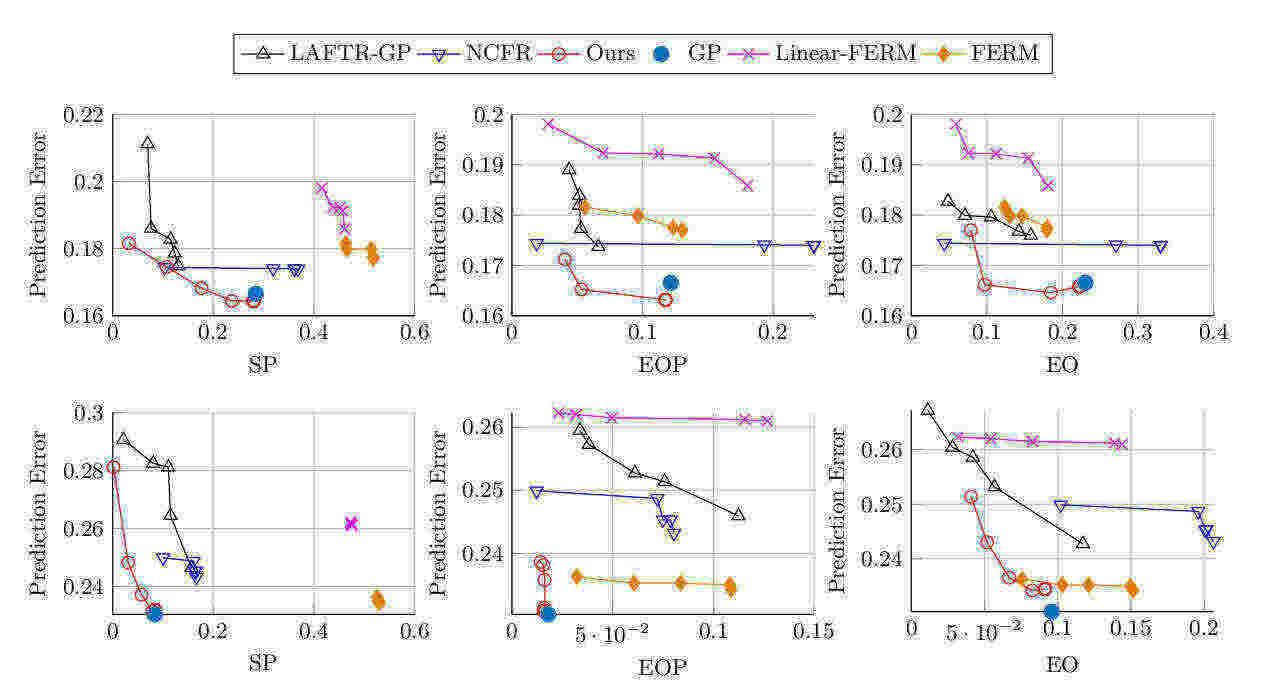
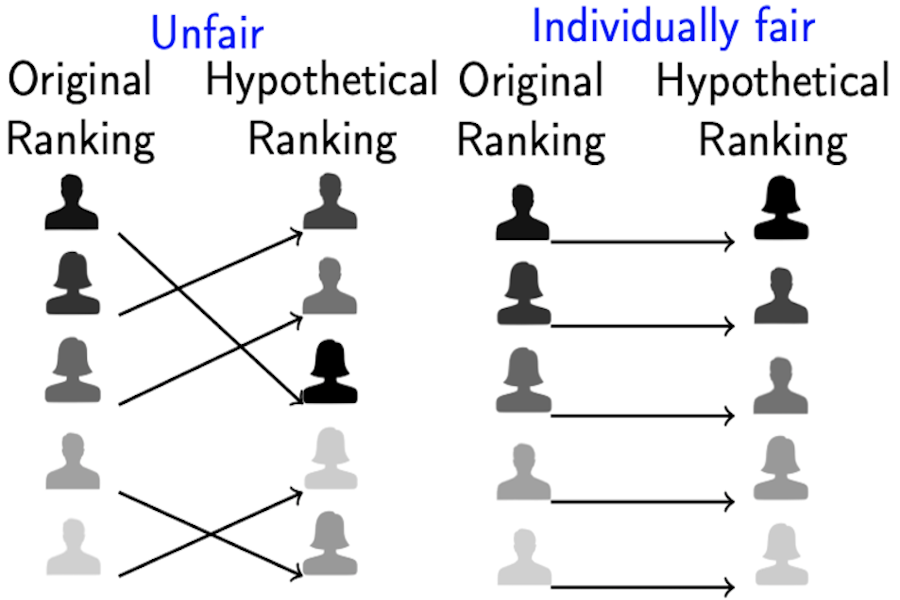
Abstract:
The ability to understand and trust the fairness of model predictions, particularly when considering the outcomes of unprivileged groups, is critical to the deployment and adoption of machine learning systems. SHAP values provide a unified framework for interpreting model predictions and feature attribution but do not address the problem of fairness directly. In this work, we propose a new definition of fairness that emphasises the role of an external auditor and model explicability. To satisfy this definition, we develop a framework for mitigating model bias using regularizations constructed from the SHAP values of an adversarial surrogate model. We focus on the binary classification task with a single unprivileged group and link our fairness explicability constraints to classical statistical fairness metrics. We demonstrate our approaches using gradient and adaptive boosting on: a synthetic dataset, the UCI Adult (Census) dataset and a real-world credit scoring dataset. The models produced were fairer and performant.