Abstract:
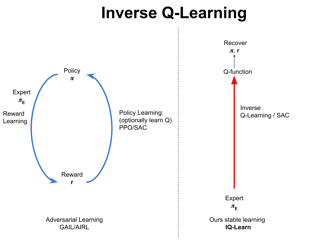
Learning reward functions from data is a promising path towards achieving scalable Reinforcement Learning (RL) for robotics. However, a major challenge in training agents from learned reward models is that the agent can learn to exploit errors in the reward model to achieve high reward behaviors that do not correspond to the intended task. These reward delusions can lead to unintended and even dangerous behaviors. On the other hand, adversarial imitation learning frameworks (Ho et al., 2016) tend to suffer the opposite problem, where the discriminator learns to trivially distinguish agent and expert behavior, resulting in reward models that produce low reward signal regardless of the input state. In this paper, we connect these two classes of reward learning methods to positive-unlabeled (PU) learning, and show that by applying a large-scale PU learning algorithm to the reward learning problem, we can address both the reward under- and over-estimation problems simultaneously. Our approach drastically improves both GAIL and supervised reward learning, without any additional assumptions.