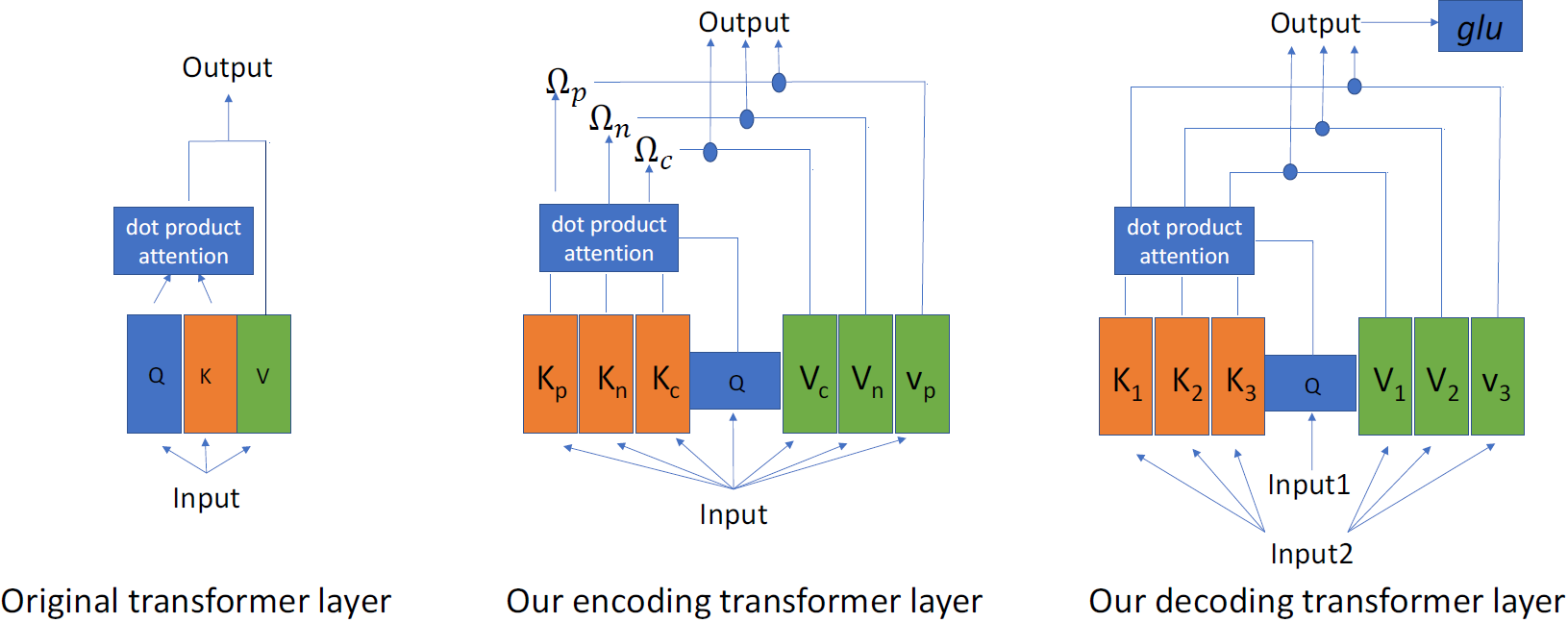
Abstract:
Multimodal Machine Translation (MMT) aims to introduce information from other modality, generally static images, to improve the translation quality. Previous works propose various incorporation methods, but most of them do not consider the relative importance of multiple modalities. Equally treating all modalities may encode too much useless information from less important modalities. In this paper, we introduce the multimodal self-attention in Transformer to solve the issues above in MMT. The proposed method learns the representation of images based on the text, which avoids encoding irrelevant information in images. Experiments and visualization analysis demonstrate that our model benefits from visual information and substantially outperforms previous works and competitive baselines in terms of various metrics.