Abstract:
Neural differential equations may be trained by backpropagating gradients via the adjoint method, which is another differential equation typically solved using an adaptive-step-size numerical differential equation solver. A proposed step is accepted if its error, \emph{relative to some norm}, is sufficiently small; else it is rejected, the step is shrunk, and the process is repeated. Here, we demonstrate that the particular structure of the adjoint equations makes the usual choices of norm (such as $L^2$) unnecessarily stringent. By replacing it with a more appropriate (semi)norm, fewer steps are unnecessarily rejected and the backpropagation is made faster. This requires only minor code modifications.
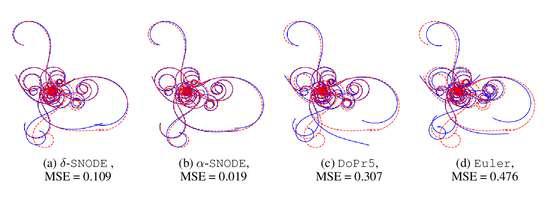
Experiments on a wide range of tasks---including time series, generative modeling, and physical control---demonstrate a median improvement of 40\% fewer function evaluations. On some problems we see as much as 62\% fewer function evaluations, so that the overall training time is roughly halved.